
The BFI National Archive is the UK’s national television archive (designated by the communications regulator Ofcom), and since 1985 we have been recording UK television off-air. For 30 years this was achieved with manual workflows involving expert curators selecting around 12% of broadcast and cataloguing the programmes in our collections database, then skilled archivists capturing the broadcasts to videotape for preservation in our Conservation Centre vaults, under controlled temperature and humidity.
In 2015 that all changed, as we ushered in an era of automation for our off-air TV capture. For seven years we have used a version of the BBC’s Redux system (generously shared by the BBC) to capture 17 channels from BBC, ITV, C4 and C5, to divide the streams into programme sections, and to store those programme sections to our digital preservation data tape libraries. That automation with Redux did not make the programmes searchable alongside the Archive’s other collections, in our Collections Information Database or its public-facing version, Collections Search, and it didn’t create accessible versions to be viewed by BFI Curators or researchers.
The BBC stopped using Redux in May 2022, and in parallel for a few years we have been seeing instability and capture problems in our BFI National Archive Redux. By 2022 Redux was 15 years old, and we decided to commit to finding a solution to replace it. We had two related priorities:
- Sustainability. We had to understand it and be able to maintain it and develop it through time
- Open Source. We prefer to use open source software where possible, to minimise reliance on commercial suppliers, and to continue our investment in open source for most of our digital preservation processes
Our project to replace Redux has taught us a lot, not least how difficult it is to achieve! To arrive at a system we feel is sustainable and open, and resistant to commercial pressures or technological obsolescence that might make the capture of UK off-air TV precarious, has been a very interesting journey. One thing is absolutely clear: the open source software community and the generosity of developers in sharing their work, and offering advice and help, has been a critical factor. We are extremely grateful for Open Source for its huge impact on our data and digital preservation work, and are committed to open sourcing our own work in turn.
Stephen McConnachie, Head of Data and Digital Preservation, BFI National Archive.
I must admit that the first time I heard about the project to replace BBC Redux, I felt a little overwhelmed. My knowledge of the BFI National Archive’s off-air recording system was fairly limited, but a recent project to integrate Electronic Programme Guide (EPG) metadata to the existing Redux workflows had provided good insight into the structure and nature of the files created. Our goal was to replicate what already existed with the aim of helping to maintain the existing workflows, but also to create a system that could be maintained and enhanced by BFI National Archive teams.
I’ve been a Developer at the BFI for just over two years, working in Stephen’s team creating automated workflows built from Bash and Python, with a focus on using open source software and standards whenever possible. Redux was celebrated for its use of open source technology, and it gave me great confidence to know that open source tools were already making off-air recording possible. It was just a question of ‘reverse engineering’ Redux, unpicking it to a point that we could rebuild a simplified version.
This started with the streams. A FreeSat Real-time Transport Protocol (RTP) stream received from a UK broadcaster generally contains one MPEG-2 video stream, two audio streams, a DVB subtitle stream and a Teletext subtitle stream. In the DVB stream is an Event Information Tables (EIT) with now and next programme guide information. This includes programme title and descriptions, broadcast channel, start time, duration and running status of a programme (running or not running). Every element in this stream is critical to our preservation requirements. Our stream hardware and software was configured by Digital Preservation Engineer John Daniel, assisted by Digital Capabilities Engineer Brian Fattorini.

We initially decided to research the potential of capturing FreeSat RTP stream data using open source software FFmpeg. We considered a method that recorded one minute chunks of stream data for a given channel that would later be reconstructed using EPG programme schedules. FFmpeg is a remarkable collection of libraries and code that have reverse engineered nearly every audio visual codec in existence. Such a gift for every digital archive! It is the secret powerhouse that underlies many successful platforms including YouTube and Apple Music. It has a wide variety of customisable commands and filters, so many that you feel anything is possible. That said, despite lots of experimentation with stream capture, cut and concatenation ‘recipes’ the perfect command eluded me. Whichever route I explored with FFmpeg, we would lose some part of a stream’s metadata, or the DVB and Teletext subtitle streams.
Thankfully, experience weighed in and John recommended a command he’d researched some years before using open source VLC software. This command uses VLC’s own demux library to record a raw RTP stream to disk, bypassing any need to re-encode the signal and preserving all of that precious stream data. The only problem that remained was a requirement to cut and concatenate these files, which again resulted in the loss of one or other element. So I rethought things, and experimented with downloading and building EPG schedules ahead of each recording day. At this time I spent some hours researching Python code use with RTP stream recording and had wonderful luck finding some Python code written in 2015 that performed a similar function. It took a schedule as a JSON file, and a stream config file provided the channel name and RTP address. With this data it looped over the schedule starting and stopping the stream programme recordings by launching an instance of a VLC recording within Python-VLC bindings. I am eternally grateful to this developer for sharing their code seven years ago under an open source licence. It’s a small selfless act that has been so impactful.
So the first STORA recording code was adapted from this code. I modernised the language and made adjustments that allowed the script to sense if the EPG schedule is modified, resulting in the reloading of the schedule in the script. This provides the potential to make programme recording adjustments when live events change the broadcast schedule. A schedule checking script was written that extracted metadata from the stream currently recording, then compared the duration of the programme in the metadata with the schedule. If the two do not match then changes are updated to the schedule for the current and next programme, while trying not to overwrite programmes still due to broadcast. This worked well, but I soon discovered that the EPG schedule recordings from initial STORA tests were not nearly as accurate or tidy as those being recorded in parallel by Redux.
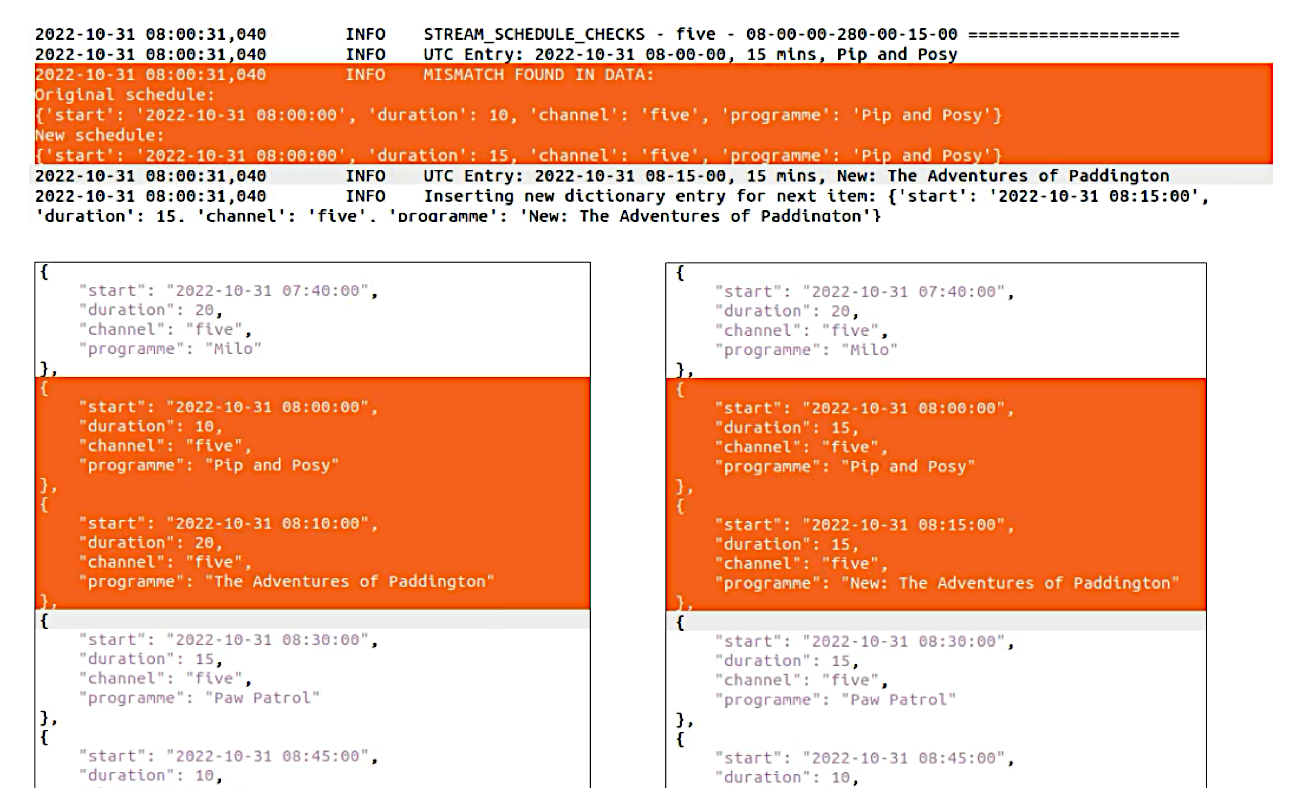
Back to the drawing board. Having learnt a little about the EIT data, I monitored live streams in VLC while watching the now/next data to see at what point each programme switched from running to not running. It was rarely anywhere near the EPG start times, but correlated with the Redux recordings. I concluded that the ‘C’ code in Redux must be using this EIT data to schedule the start and stop time of programmes.
I looked for open source solutions that would allow me to capture this stream data, and found a VLC library fork called libdvbtee on GitHub. The dvbtee software for the Libdvbtee library would read EIT data and output it as a line of JSON formatted text. This allowed me to import the data easily into Python and use it to trigger stream recordings. The only problem to be overcome was the requirement for a new stream that could be used by dvbtee, as it would not read this data from the RTP stream. John configured User Datagram Protocol (UDP) streams for each channel, and I was able to use this to obtain the information required to build an alternative script. It triggers recordings when the ‘EventID’ for a stream changes, and when the running status equals ‘4’, which means running. This script does not need to rely on the EPG metadata schedules, and runs endlessly. But I did build in an option to stop recording with a control JSON file should a channel need to be worked upon.
Today the STORA scripts use both scripting approaches, with three channels recording from the EPG schedules, and the remaining 14 channels using this ‘running status’ script. This is simply because the EIT data is not reliable for three channels, Channel4, More4 and Film4 – and these have been the channels suffering from the most significant recording problems by Redux.
Now that we had successful programme recordings, all that was left to replicate is the extraction of the same EIT data to a CSV file, used by Python ingest scripts to pass programme information to the BFI National Archive’s Collections Information Database (CID). This was written using Python and open source software MediaInfo to extract the programme metadata directly from the .ts file once stream recording had completed. The data is then reformatted and output to a CSV file. Finally we needed to replicate the subtitle extraction script, which like Redux uses open source software CCextractor to read all the spoken word from the stream into a webvtt formatted file. Another Python script manages this and the resulting subtitle.vtt file is also imported into the programme’s item record in CID, where the data is searchable.
I’m delighted to say that we launched STORA in October of this year, sidelining Redux to a temporary supporting role until we have a duplicate STORA back-up system developed. And for World Digital Preservation Day (first Thursday each November) I’m thrilled to share the complete suite of STORA scripts via our open source GitHub repository. There are 47 scripts in total that make up STORA off-air recording scripts, including those discussed above and also scripts that manage the immediate restarting of any channel recordings that may suffer an interruption. I’d like to express my gratitude to my colleagues who assisted with this research project, Stephen McConnachie, John Daniel and Brian Fattorini. And of course we must thank the international developers and archivists who write and maintain the open source software that made this, and many BFI National Archive workflows, possible.
Joanna White, Collections and Information Developer, BFI National Archive.